
데이터 분석의 세계에 발을 들여놓으면, 어느 순간 '산포도'라는 녀석과 마주하게 됩니다. 처음엔 좀 낯설지만, 알고 나면 통계 데이터 분석의 핵심 무기가 되는 아주 매력적인 녀석이죠. 이 포스팅에서는 산포도의 개념과 함께 분산, 표준편차, 범위를 꼼꼼하게 살펴보고, 실제 데이터 분석에서 어떻게 활용하는지 자세히 알려드릴게요. 데이터 분석에 막 입문하신 분들도, 어느 정도 경험이 있으신 분들도, 다 함께 산포도의 세계로 떠나볼까요? 자, 준비됐나요? 그럼 시작해 봅시다!
산포도: 데이터의 퍼짐 정도를 측정하는 방법

산포도는 데이터가 얼마나 퍼져 있는지를 나타내는 척도입니다. 평균값만으로는 데이터 전체의 분포를 정확하게 알 수 없어요. 예를 들어, 두 집단의 평균 시험 점수가 같더라도, 한 집단은 점수가 몰려 있고 다른 집단은 점수가 넓게 퍼져 있을 수 있잖아요? 이때 산포도는 이런 차이를 명확하게 보여주는 역할을 합니다. 산포도가 크다는 것은 데이터가 평균으로부터 멀리 퍼져 있다는 것을 의미하고, 산포도가 작다는 것은 데이터가 평균값에 가깝게 모여 있다는 것을 의미합니다. 쉽게 말해, 산포도는 데이터의 '흩어짐 정도'를 측정하는 지표라고 생각하면 됩니다. 그리고 이 산포도를 측정하는 대표적인 방법으로는 분산, 표준편차, 그리고 범위가 있습니다.
분산: 데이터의 퍼짐 정도를 수치로 나타내다

분산은 데이터의 산포도를 나타내는 가장 기본적인 지표입니다. 각 데이터 값이 평균으로부터 얼마나 떨어져 있는지를 제곱하여 평균한 값으로, 데이터가 얼마나 평균으로부터 흩어져 있는지를 정량적으로 나타냅니다. 분산이 클수록 데이터가 평균으로부터 멀리 퍼져 있고, 분산이 작을수록 데이터가 평균에 가깝게 모여 있다는 것을 의미합니다. 그런데 왜 제곱을 할까요? 그 이유는 편차(데이터 값 - 평균)의 합이 항상 0이 되기 때문입니다. 제곱을 하면 음수 값이 양수로 바뀌어 합이 0이 되는 문제를 해결할 수 있습니다. 수식으로 나타내면 다음과 같습니다.
분산 = Σ(xi - μ)² / N
여기서 xi는 각 데이터 값, μ는 평균, N은 데이터의 개수를 나타냅니다. 분산은 단위가 데이터의 제곱 단위이기 때문에 직관적으로 이해하기 어려운 측면이 있습니다. 그래서 표준편차가 등장하는 거죠!
표준편차: 분산의 제곱근, 더욱 직관적인 산포도 측정

표준편차는 분산의 제곱근으로, 분산과 같은 정보를 담고 있지만, 원래 데이터와 같은 단위를 사용하기 때문에 분산보다 직관적으로 이해하기 쉽습니다. 표준편차가 작을수록 데이터가 평균에 밀집되어 있고, 클수록 데이터가 평균으로부터 넓게 퍼져 있다는 것을 의미합니다. 표준편차는 분산의 단점인 제곱 단위 문제를 해결해주는 훌륭한 지표인 셈이죠. 분산을 계산한 후 제곱근을 구하면 표준편차를 얻을 수 있습니다. 수식으로 표현하면 다음과 같아요.
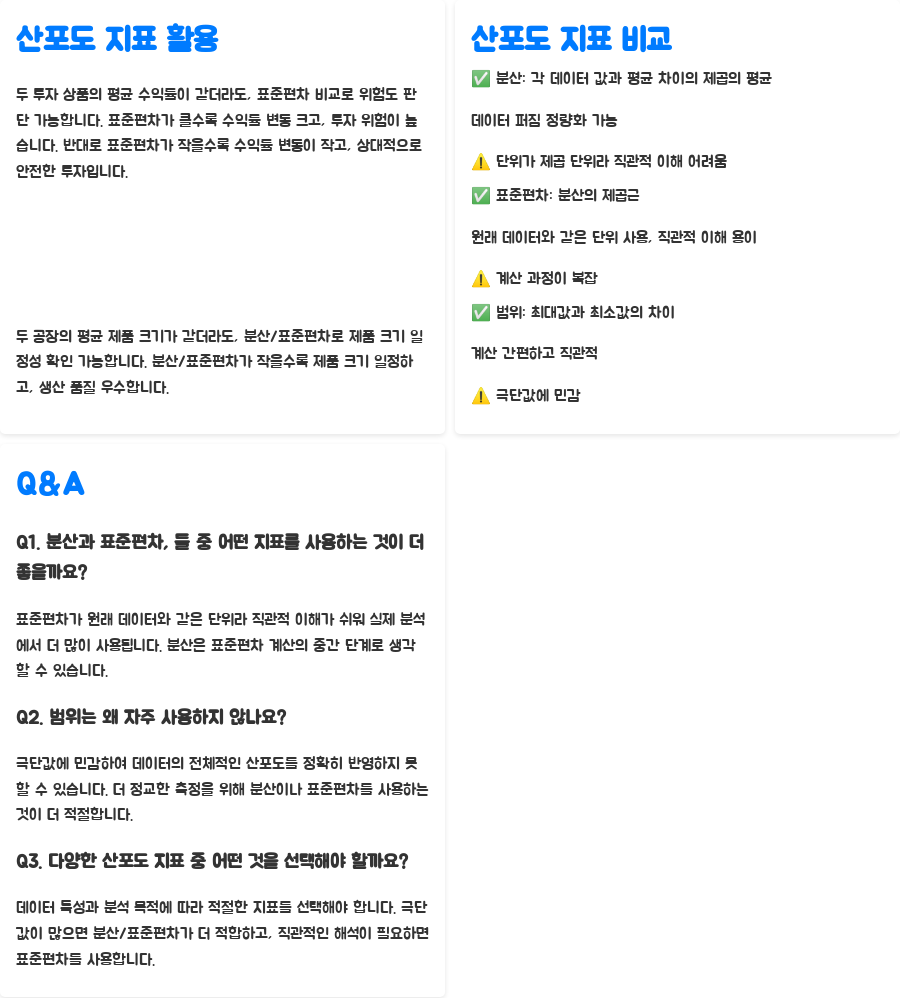
표준편차 = √분산
범위: 최대값과 최소값의 차이, 가장 간단한 산포도 측정

범위는 데이터 집합의 최대값과 최소값의 차이를 의미합니다. 가장 간단하고 직관적으로 산포도를 파악할 수 있는 방법입니다. 최대값과 최소값만 알면 쉽게 계산할 수 있죠. 범위가 클수록 데이터가 넓게 퍼져 있고, 범위가 작을수록 데이터가 밀집되어 있음을 나타냅니다. 하지만 범위는 극단값에 매우 민감하다는 단점이 있습니다. 극단값이 하나만 바뀌어도 범위가 크게 달라질 수 있으므로, 데이터의 전체적인 산포도를 정확하게 나타내지는 못할 수도 있습니다.
데이터 분석에서 산포도 활용하기: 실제 예시와 함께
이제 산포도 지표들을 실제 데이터 분석에 어떻게 적용하는지 알아볼까요? 예를 들어, 두 개의 투자 상품 A와 B의 수익률 데이터가 있다고 가정해봅시다. 두 상품의 평균 수익률이 같더라도, 표준편차를 비교하면 어느 상품이 더 위험한지를 판단할 수 있습니다. 표준편차가 큰 상품은 수익률의 변동이 크다는 것을 의미하며, 투자 위험이 더 크다고 해석할 수 있겠죠. 반대로 표준편차가 작은 상품은 수익률 변동이 작아 상대적으로 안전한 투자라고 볼 수 있습니다.
또 다른 예로, 두 공장에서 생산된 제품의 크기를 비교한다고 생각해 봅시다. 두 공장의 평균 제품 크기가 동일하더라도, 분산이나 표준편차를 통해 어느 공장의 제품 크기가 더 일정하게 생산되는지 확인할 수 있습니다. 분산이나 표준편차가 작은 공장은 제품의 크기가 더 일정하게 관리되고 있다는 것을 나타내며, 생산 품질이 더 우수하다고 판단할 수 있습니다. 이처럼 산포도는 데이터의 분포 특성을 파악하고, 다양한 상황에 맞춰 적절한 해석을 내리는 데 중요한 역할을 합니다.
| 분산 | 각 데이터 값과 평균의 차이의 제곱의 평균 | 데이터의 퍼짐 정도를 정량적으로 나타냄 | 단위가 데이터의 제곱 단위이므로 직관적 이해 어려움 |
| 표준편차 | 분산의 제곱근 | 원래 데이터와 같은 단위 사용, 직관적 이해 용이 | 계산 과정이 분산보다 복잡함 |
| 범위 | 최대값과 최소값의 차이 | 계산이 간단하고 직관적 | 극단값에 민감함 |
지표 설명 장점 단점
Q1. 분산과 표준편차, 둘 중 어떤 지표를 사용하는 것이 더 좋을까요?
A1. 분산과 표준편차는 서로 밀접한 관련이 있고, 데이터의 산포도를 나타내는 데 모두 유용한 지표입니다, 하지만 표준편차가 원래 데이터와 같은 단위를 사용하기 때문에 직관적인 이해가 더 쉬워 실제 분석에서는 표준편차를 더 많이 사용합니다, 분산은 표준편차를 계산하는 중간 단계로 생각할 수 있죠.
Q2. 범위는 왜 자주 사용하지 않나요?
A2. 범위는 계산이 간편하지만, 극단값(최대값과 최소값)에 매우 민감하다는 단점이 있습니다, 극단값 하나만 바뀌어도 범위가 크게 달라질 수 있기 때문에 데이터의 전체적인 산포도를 정확하게 반영하지 못할 수도 있어요, 그래서 더욱 정교한 산포도 측정을 위해서는 분산이나 표준편차를 사용하는 것이 더 적절합니다.
Q3. 다양한 산포도 지표 중 어떤 것을 선택해야 할까요?
A3. 데이터의 특성과 분석 목적에 따라 적절한 산포도 지표를 선택해야 합니다, 데이터에 극단값이 많다면 범위보다는 분산이나 표준편차가 더 적합합니다, 또한, 데이터의 단위를 고려하여 직관적인 해석이 필요하다면 표준편차를 사용하는 것이 좋습니다, 어떤 지표를 선택하든, 데이터의 특성을 잘 이해하고 분석 목적에 맞게 지표를 선택하는 것이 중요합니다.
이 포스팅이 여러분의 데이터 분석 여정에 조금이나마 도움이 되었기를 바랍니다, 다음 시간에는 더욱 유익한 통계 이야기로 다시 찾아뵙겠습니다, 궁금한 점이 있다면 언제든지 댓글 남겨주세요.



